这篇笔记是对git使用中自动merge算法的好奇,查找了一些资料,简单做了个总结,留以存档。
Git的组成
工作区(workspace)
就是我们当前工作空间,也就是我们当前能在本地文件夹下面看到的文件结构。初始化工作空间或者工作空间clean的时候,文件内容和index暂存区是一致的,随着修改,工作区文件在没有add到暂存区时候,工作区将和暂存区是不一致的。
暂存区(index)
老版本概念也叫Cache区,就是文件暂时存放的地方,所有暂时存放在暂存区中的文件将随着一个commit一起提交到local repository 此时 local repository里面文件将完全被暂存区所取代。暂存区是git架构设计中非常重要和难理解的一部分。后续会有专门的文章研究暂存区。
本地仓库(local repository)
git 是分布式版本控制系统,和其他版本控制系统不同的是他可以完全去中心化工作,你可以不用和中央服务器(remote server)进行通信,在本地即可进行全部离线操作,包括log,history,commit,diff等等。 完成离线操作最核心是因为git有一个几乎和远程一样的本地仓库,所有本地离线操作都可以在本地完成,等需要的时候再和远程服务进行交互。
远程仓库(remote repository)
中心化仓库,所有人共享,本地仓库会需要和远程仓库进行交互,也就能将其他所有人内容更新到本地仓库把自己内容上传分享给其他人。结构大体和本地仓库一样。
状态模型
状态流转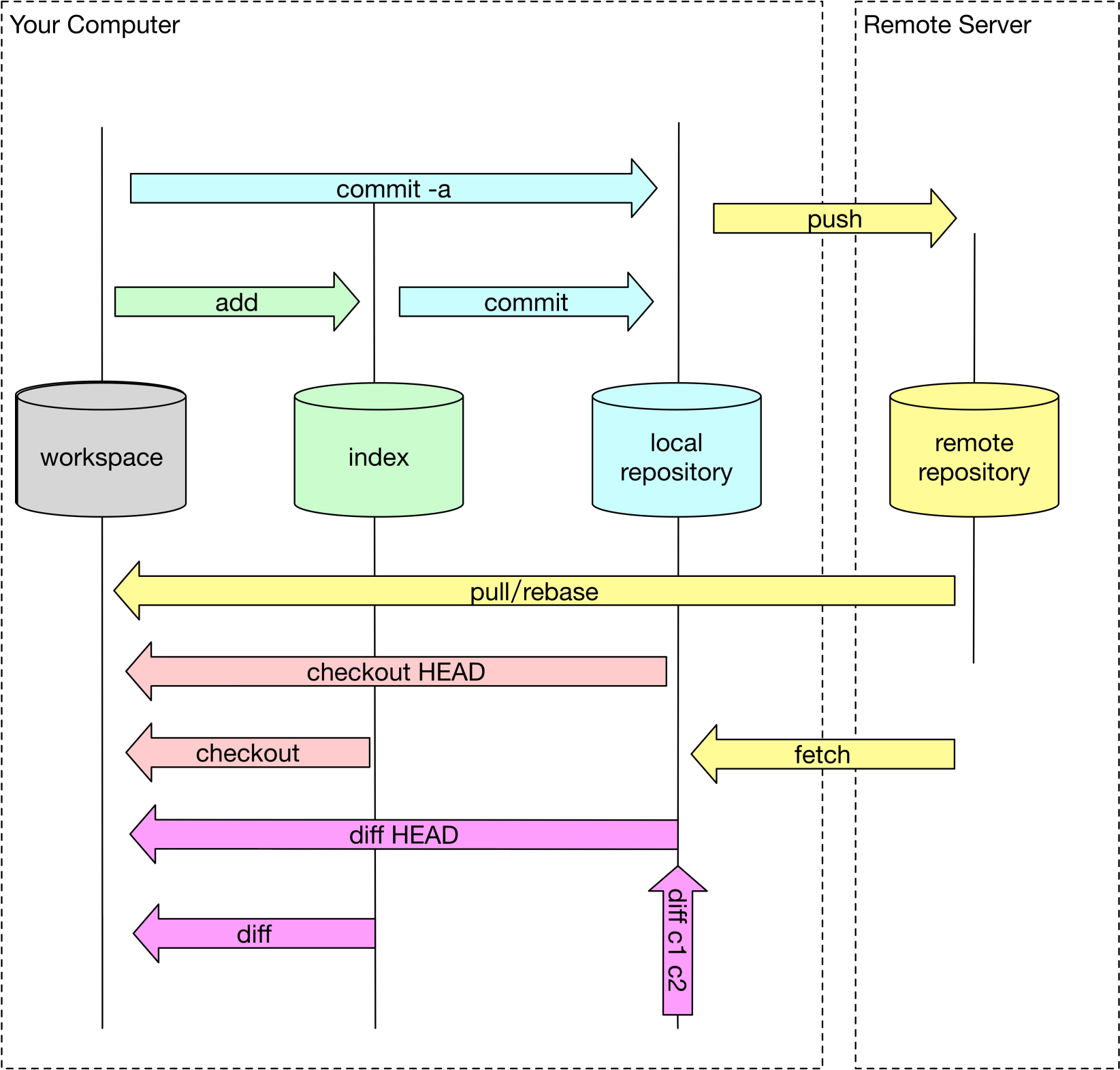
文件变化
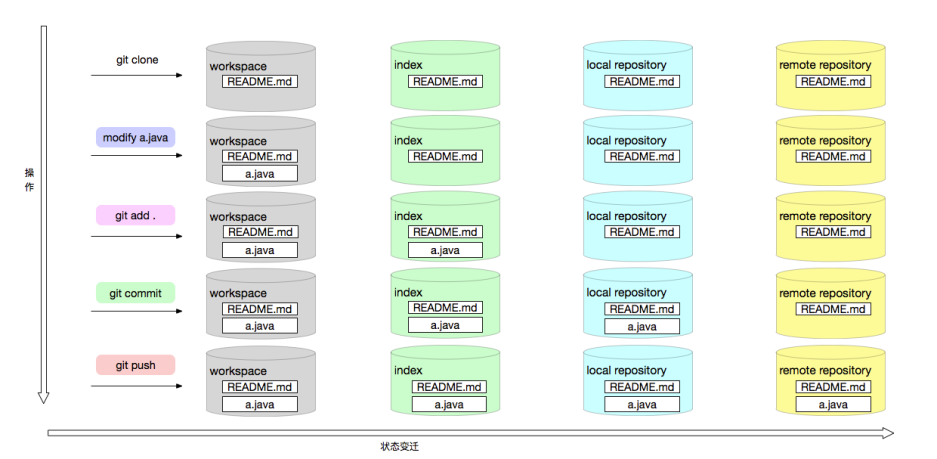
存储模型
git 区别与其他 vcs 系统的一个最主要原因之一是:git 对文件版本管理和其他vcs系统对文件版本的实现理念完成不一样。这也就是git 版本管理为什么如此强大的最核心的地方。
Svn 等其他的VCS对文件版本的理念是以文件为水平维度,记录每个文件在每个版本下的delta改变。
Git 对文件版本的管理理念却是以每次提交为一次快照,提交时对所有文件做一次全量快照,然后存储快照引用。
Git 在存储层,如果文件数据没有改变的文件,Git只是存储指向源文件的一个引用,并不会直接多次存储文件,这一点可以在pack 文件中看见。
如下图所示: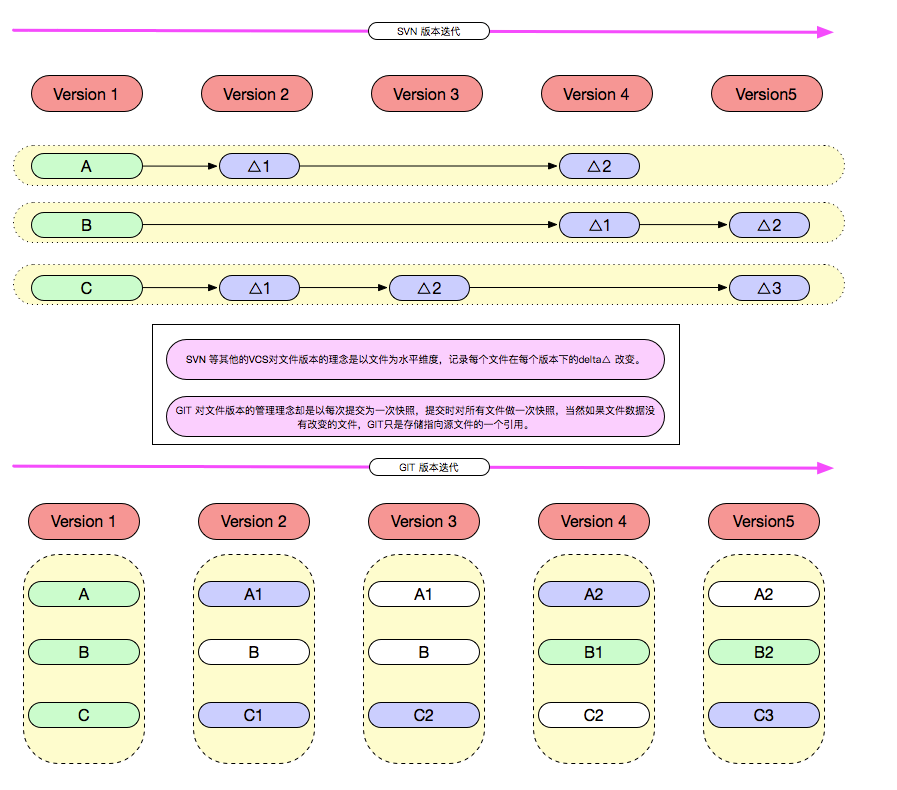
Merge算法
Q&A
Q: git merge 是用时间先后决定merge结果的,后面会覆盖前面的?
A: git 是分布式的文件版本控制系统,在分布式环境中时间是不可靠的,git是靠三路合并算法进行合并的。
git merge 只要两行不相同就一定会报冲突,叫人工解决?
答:git 尽管两行内容不一样,smart git 会进行取舍,当git无法进行取舍的时候才会进行人工解决冲突。
合并算法
二路合并
二路合并算法就是讲两个文件进行逐行对别,如果行内容不同就报冲突。
1 | //Mine |
1 | //Theirs |
- Mine 代表你本地修改
- Theirs 代表其他人修改
假设对于同一个文件,出现你和其他人一起修改,此时如果git来进行合并,git就懵逼了,因为Git既不敢得罪你(Mine),也不能得罪他们(Theirs) ,无理无据,git只能让你自己搞了,但是这种情况太多了而且其实也没有必要。
三路合并
三路合并就是先找出一个基准,然后以基准为Base 进行合并,如果2个文件相对基准(base)都发生了改变 那git 就报冲突,然后让你人工决断。否则,git将取相对于基准(base)变化的那个为最终结果。
- Base 代表上一个版本,即公共祖先
- Mine 代表你本地修改
- Theirs 代表其他人修改
- Merge 代表git进行merge后的结果
自动merge场景
1 | //Base |
1 | //Mine |
1 | //Theirs |
1 | //Merge |
这样当git进行合并的时候,git就知道是其他人修改了,本地没有更改,git就会自动把最终结果变成如下,这个结构也是大多merge工具的常见布局,比如IDEA
手动merge场景
需要手动merge的场景就是Mine和Theis都对相同的
1 | //Base |
1 | //Mine |
1 | //Theirs |
1 | //Merge |
在这种情况下,Mine和Theirs都对分支进行了修改,git重新遇到了二路合并的问题,需要手动解决冲突。
三路合并示例
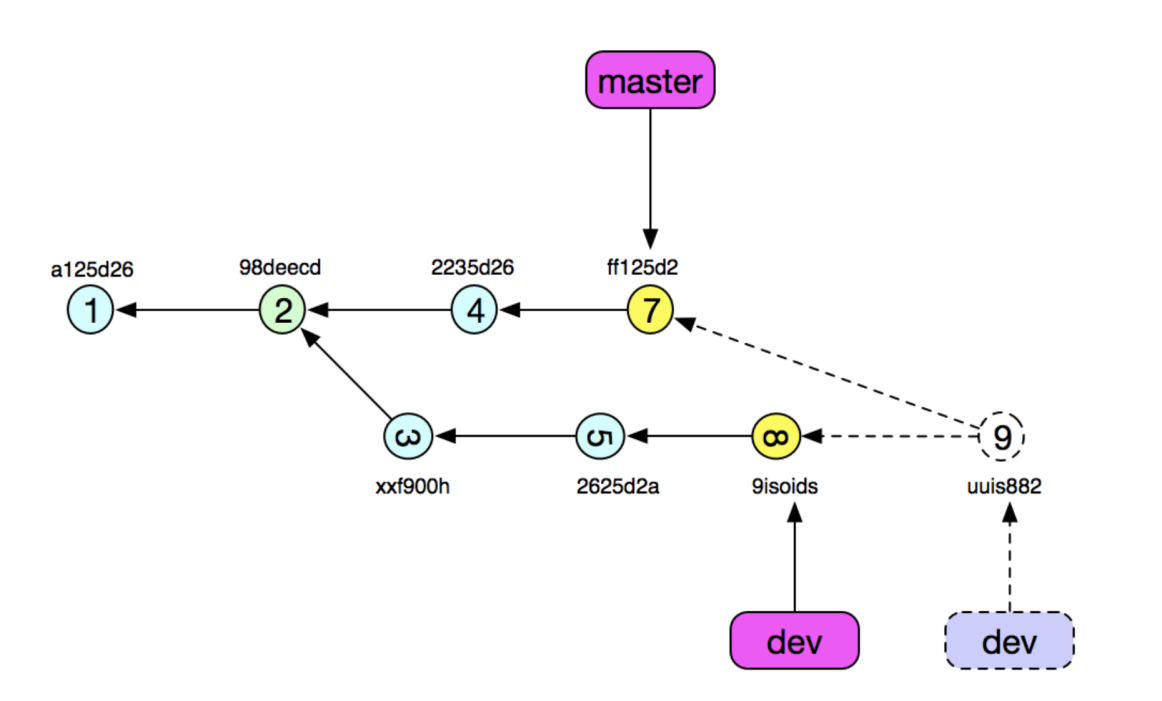
- 上面①~⑨代表一个个修改集合(commit),每个commit都有一个唯一7位SHA-1唯一表示。
- ①,②,④,⑦修改集串联起来就是一个链,此时用master指向这个集合就代表master分支,分支本质是一个快照。
- 同样dev分支也是由一个个commit组成
现在在dev分支上由于各种原因要运行git merge master需要把master分支的更新合并到dev分支上,本质上就是合并修改集 ⑦(Mine) 和 ⑧(Theirs) ,此时我们要利用DAG(有向无环图)相关算法找到我们公共的祖先 ②(Base)然后进行三方合并,最后合并生成 ⑨
1 | //找出公共祖先的commitId(Base) |
在实际开发环境中,分支的Graph更为复杂,但基本的算法原理不变。
递归三路合并
公共祖先不唯一问题
抽象化
1 | ---1---o---A |
具体化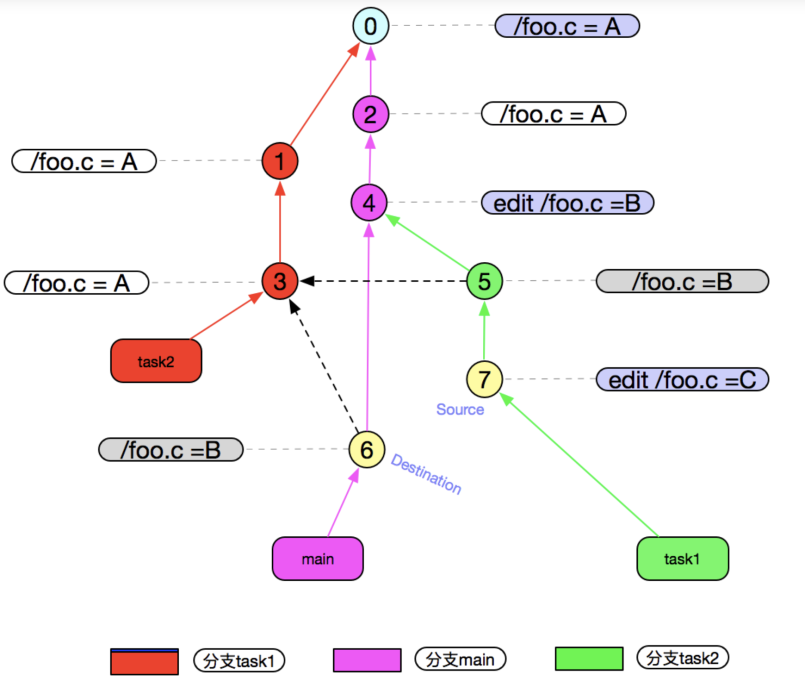
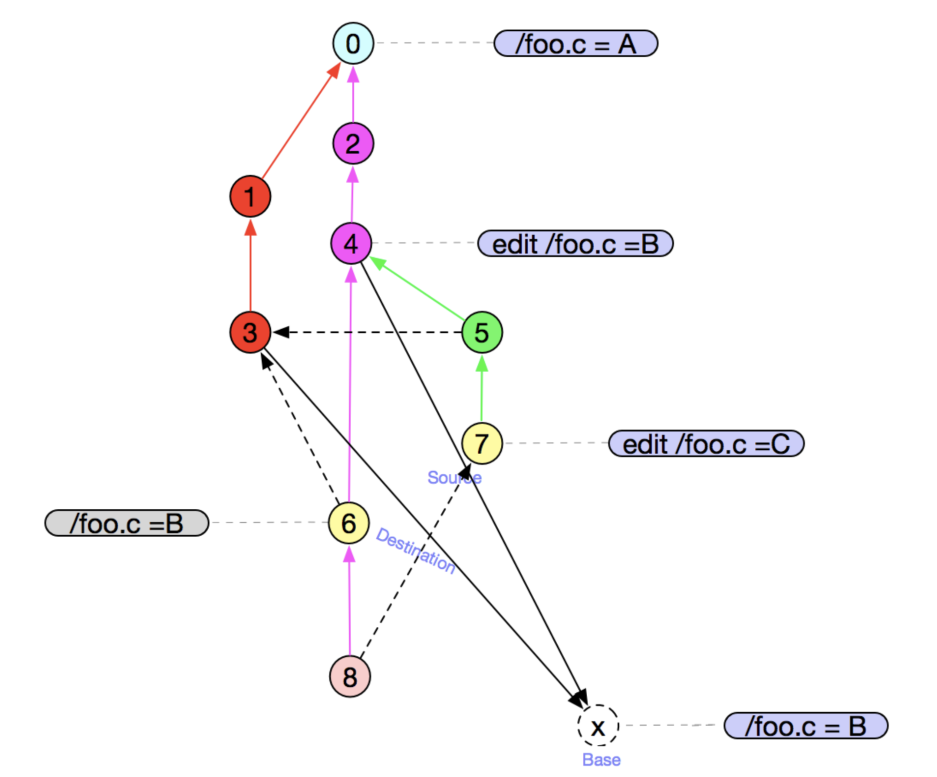
(这部分图有点问题,阅读理解困难,可跳过直接看问题)
简短描述下 如何会出现上面的图:
- 在master分支上新建文件foo.c ,写入数据”A”到文件里面
- 新建分支task2 git checkout -b task2 0,0 代表commit Id
- 新建并提交commit ① 和 ③
- 切换分支到master,新建并提交commit ②
- 新建并修改foo.c文件中数据为”B”,并提交commit ④
- merge commit ③ git merge task2,生成commit ⑥
- 新建分支task1 git chekcout -b ④
- 在task1 merge ③ git merge task2 生成commit ⑤
- 新建commit ⑦,并修改foo.c文件内容为”C”
- 切换分支到master上,并准备merge task1 分支(merge ⑦-> ⑥)
我们如果要合并 ⑦(source) -> ⑥(destination)
会发现有⑥和⑦有两个最佳公共祖先③和④
以③为公共祖先时需要手动解决冲突 /foo.c = BC???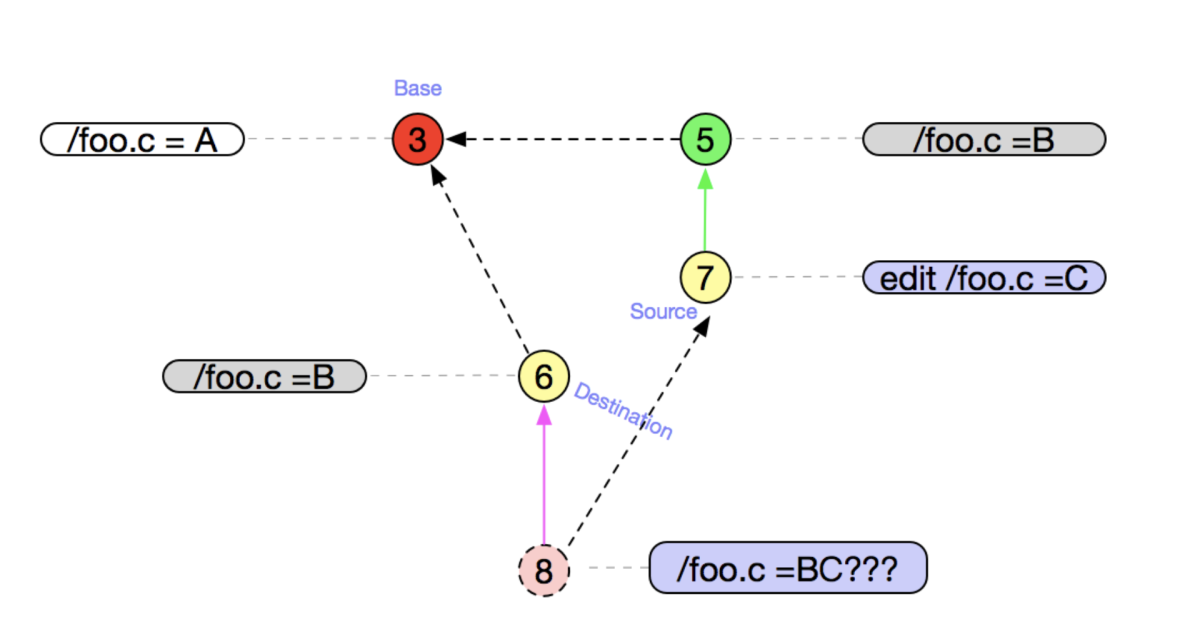
以④作为公共祖先将得到 /foo.c=C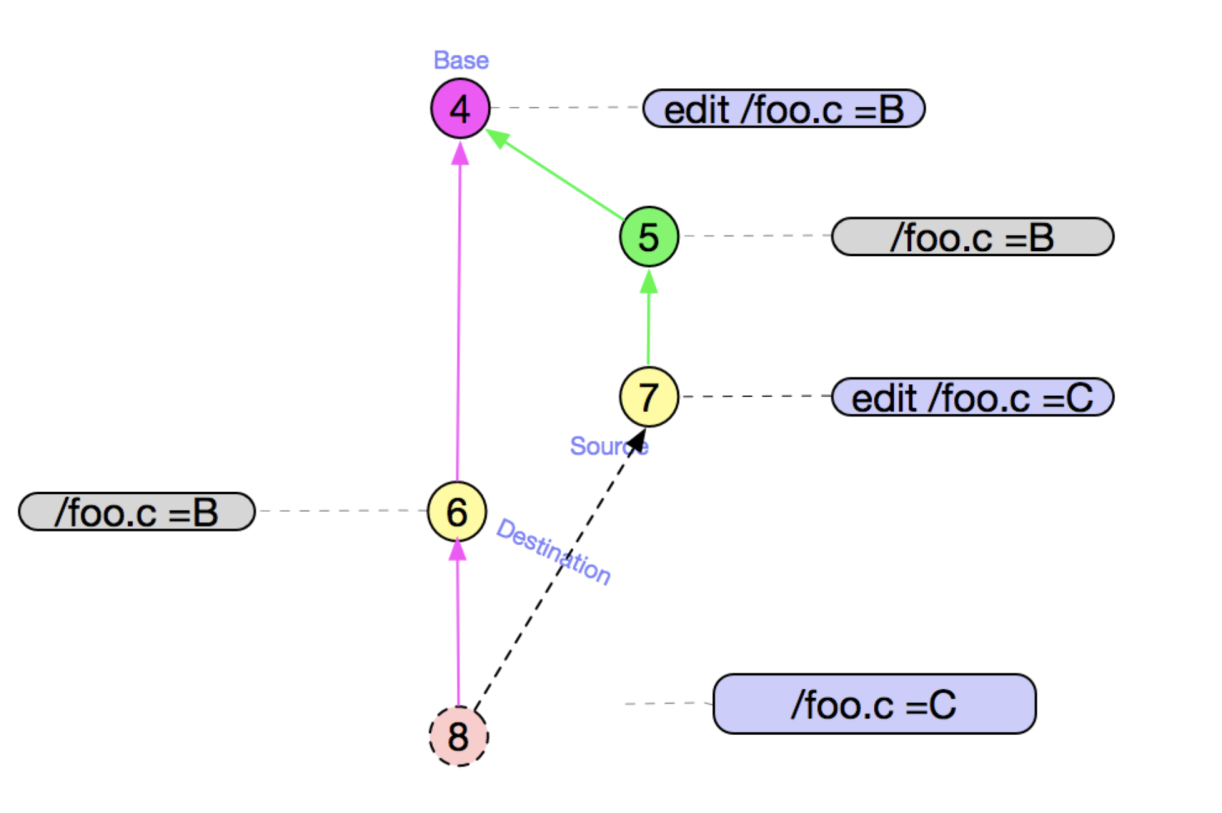
git解法
git 既不是直接用③,也不是用④,而是将2个祖先进行合并成一个虚拟的 X /foo.c = B。因为③ 和 ④ 公共祖先是 0/foo.c = A,根据③和④以及他们的公共祖先进行递归三路归并进行合成的到虚拟的 X /foo.c = B。