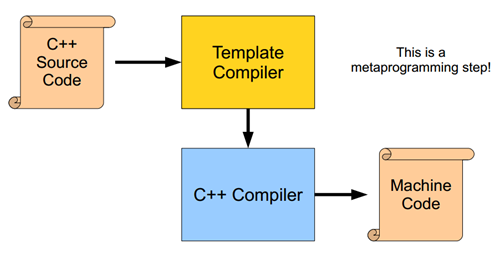
这篇作为模板编程的第四篇,主要讲述一下一些元模板编程的特性。
模板元编程概念 C++ 模板的特性最早是为了支撑泛型,所谓的模板元编程其实是由于意外发现C++ 模板是图灵完备的(Turing-complete)后的一个衍生物。如果C++模板语法可以模拟图灵机的话,那么理论上来说 C++ 模板可以执行任何计算任务,但实际上因为模板是编译期计算,其能力受到具体编译器实现的限制(如递归嵌套深度,C++11 要求最多1024,C++98 要求最多 17)。
模板元编程范式 从编程范型(programming paradigm)上来说,C++ 模板是函数式编程(functional programming),它的主要特点是:函数调用不产生任何副作用(没有可变的存储),用递归形式实现循环结构的功能。C++ 模板的特例化提供了条件判断能力,而模板递归嵌套提供了循环的能力,这两点使得其具有和普通语言一样通用的能力(图灵完备性)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <iostream> template <typename T, int i=1 >class someComputing {public :typedef volatile T* retType; enum { retValume = i + someComputing<T, i-1 >::retValume }; static void f () "someComputing: i=" << i << '\n' ; }}; template <typename T> class someComputing <T, 0 > {public :enum { retValume = 0 };}; template <typename T>class codeComputing {public :static void f () f (); } }; int main () someComputing<int >::retType a=0 ; std::cout << sizeof (a) << '\n' ; std::cout << someComputing<int , 500 >::retValume << '\n' ; codeComputing<someComputing<int , 99 >>::f (); std::cin.get (); return 0 ; }
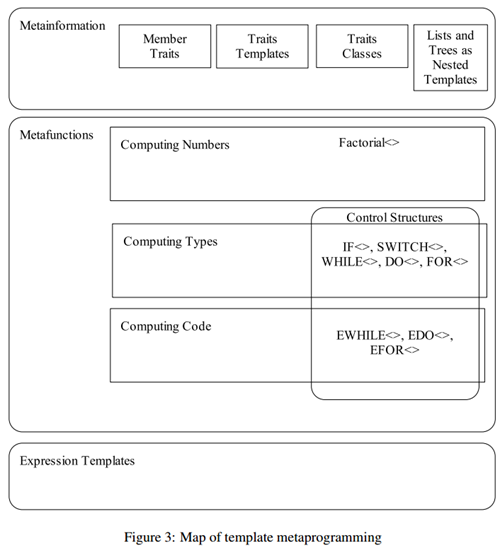
编程的概览图如下:
模板元编程应用 编译期间数值计算 前面已经有了利用模板实现阶乘的示例代码,下面给出一份更简单的用模板实现求和的示例代码来说明模板在编译期间实现数值计算的具体原理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <iostream> template <int N>class sumt {public : static const int ret = sumt<N-1 >::ret + N;}; template <>class sumt <0 >{public : static const int ret = 0 ;}; int main () std::cout << sumt<5 >::ret << '\n' ; std::cin.get (); return 0 ; }
当编译器遇到 sumt<5> 时,试图实例化之,sumt<5> 引用了 sumt<5-1> 即 sumt<4>,试图实例化 sumt<4>,以此类推,直到 sumt<0>,sumt<0> 匹配模板特例,sumt<0>::ret 为 0,sumt<1>::ret 为 sumt<0>::ret+1 为 1,以此类推,sumt<5>::ret 为 15。值得一提的是,虽然对用户来说程序只是输出了一个编译期常量 sumt<5>::ret,但在背后,编译器其实至少处理了 sumt<0> 到 sumt<5> 共 6 个类型。
循环展开 部分古早的观点会认为,模板元编程会在循环展开中起到作用,例如一篇早期的测试:http://web.archive.org/web/20050310091456/http://osl.iu.edu/~tveldhui/papers/Template-Metaprograms/meta-art.html
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #include <utility> void bubbleSort (int * data, int n) for (int i=n-1 ; i>0 ; --i) { for (int j=0 ; j<i; ++j) if (data[j]>data[j+1 ]) std::swap (data[j], data[j+1 ]); } } inline void bubbleSort4 (int * data) #define COMP_SWAP(i, j) if (data[i]>data[j]) std::swap(data[i], data[j]) COMP_SWAP (0 , 1 ); COMP_SWAP (1 , 2 ); COMP_SWAP (2 , 3 ); COMP_SWAP (0 , 1 ); COMP_SWAP (1 , 2 ); COMP_SWAP (0 , 1 ); } class recursion { };void bubbleSort (int * data, int n, recursion) if (n<=1 ) return ; for (int j=0 ; j<n-1 ; ++j) if (data[j]>data[j+1 ]) std::swap (data[j], data[j+1 ]); bubbleSort (data, n-1 , recursion ()); } template <int i, int j>inline void IntSwap (int * data) if (data[i]>data[j]) std::swap (data[i], data[j]); } template <int i, int j>inline void IntBubbleSortLoop (int * data) IntSwap <j, j+1 >(data); IntBubbleSortLoop<j<i-1 ?i:0 , j <i-1 ?(j+1 ):0 >(data); } template <>inline void IntBubbleSortLoop <0 , 0 >(int *) { }template <int n>inline void IntBubbleSort (int * data) IntBubbleSortLoop <n-1 , 0 >(data); IntBubbleSort <n-1 >(data); } template <>inline void IntBubbleSort <1 >(int * data) { }
我复现了该程序,并且使用了如下代码进行测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int main () const int num=100000000 ; int data[4 ]; int inidata[4 ]={3 ,4 ,2 ,1 }; auto t1 = std::chrono::high_resolution_clock::now (); for (int i=0 ; i<num; ++i) { memcpy (data, inidata, 4 ); bubbleSort (data, 4 ); } std::chrono::duration<double , std::milli> t1_cost = std::chrono::high_resolution_clock::now () - t1; auto t2 = std::chrono::high_resolution_clock::now (); for (int i=0 ; i<num; ++i) { memcpy (data, inidata, 4 ); bubbleSort4 (data); } std::chrono::duration<double , std::milli> t2_cost = std::chrono::high_resolution_clock::now ()-t2; auto t3 = std::chrono::high_resolution_clock::now (); for (int i=0 ; i<num; ++i) { memcpy (data, inidata, 4 ); IntBubbleSort <4 >(data); } std::chrono::duration<double , std::milli> t3_cost = std::chrono::high_resolution_clock::now ()-t3; std::cout << "迭代/模板 = " <<t1_cost/t3_cost << '\t' << "迭代展开/模板 = " <<t2_cost/t3_cost << '\n' ; std::cin.get (); return 0 ; }
对此,在没有开启编译器优化的情况下,我的复现结果如下:
1 迭代/模板 = 0.347768 迭代展开/模板 = 0.144893
可见,我们得到了超出预期的结果,不管是普通的迭代,还是手动的循环展开,在没有编译器优化的情况下都超过了通过模板进行展开的效率,这部分的差异应该是近十几年编译器的优化更新造成的,更具体的原因需要留待进一步的探索。
参考链接 https://www.cnblogs.com/liangliangh/p/4219879.html