
之前在聊到性能优化的时候,非常泛泛而谈得聊了一些技巧,在接下来几篇博客中,打算专门细化一下,当然也不是从头开始,算是整合之前的一些散落的随记吧。
这篇是关于无锁编程的原理介绍,在开篇的时候,我先阐述一下我的理解:
真正的无锁编程并不存在,它只是无限地将锁的颗粒度降低。
无锁编程的背景
需要互斥锁的原因
在传统的多线程、多进程的编程模式中,互斥锁是一种不可或缺的工具。
在本质上,可以归结为两种原因:
- 需要安全地并发访问共享资源。
- 需要在共享资源上控制访问顺序。
它们都将确保代码在的某些线程不安全部分不会并发执行或者以错误的顺序执行。
互斥锁存在的问题
互斥锁的本质
互斥锁本质上作为一个状态值,本身和一个共享资源绑定在一起,逻辑上可以简单将互斥锁理解为如下结构。
1 | struct mutex_lock{ |
在 CPU 的其中一个核上的线程在执行到加锁逻辑时,会根据这个锁的 owner 找到其对应的状态 state 值,会根据当前状态会有两种可能:
- 如果 state 是未被锁的状态,则当前 CPU 核正常执行该线程接下来的代码,同时修改 state 值为已被锁的状态,并将状态同步给其他 CPU 核;
- 如果 state 是已被锁的状态,则当前 CPU 核不再继续往下执行该线程代码,而是将线程加入等待队列wait_threads,等待互斥锁退出后重新被调度。
在第二种情况中,由于state 被锁,所以导致了当前CPU正在执行的线程被挂起,操作系统会给核分配其他活动着的线程的代码来执行,也就产生了“线程切换”。
互斥锁带来的开销
互斥锁本身的开销
使用锁需要额外的资源,例如锁的内存空间,以及用于初始化、销毁、获取和释放锁的 CPU 资源。我们使用锁来保护对共享资源的访问的任何地方,都会有额外的开销。
线程切换的开销
一次线程切换意味着3us左右的开销(粗略数据,根据不同的CPU规格存在差异)
直接开销:
- 切换页表全局目录
- 切换内核态堆栈
- 切换硬件上下文(寄存器内数据,包括下一条指令地址,执行中函数栈顶、栈底地址等)
- 刷新TLB(在切换后进行页表查询时将全部击穿TLB)
间接开销:
间接开销主要在于切换之后,各种缓存并不热,速度运行会变慢慢一些。如果始终都在一个CPU上调度还好一些,如果跨CPU的话,之前热起来的TLB、L1、L2、L3因为运行的进程已经变了,所以以局部性原理cache起来的代码、数据也都没有用了,导致新进程穿透到内存的IO会变多。
感兴趣的同学可以参考这篇文章:
https://www.usenix.org/legacy/events/expcs07/papers/2-li.pdf
无锁编程原理
继续回到上文的需要互斥锁的原因往下说,想要完全不存在锁的话,那就要从根源上保证访问共享资源时候不会冲突,这显然是无法做到的。
所以,身为程序开发者,只能从另外的角度来消除锁的影响。
从自旋锁说起
直接针对上面问题出发,我们已经得到了互斥锁的开销来自于线程切换的结论。
那么如果针对线程切换的开销的话,那就用自旋锁来代替互斥锁。当发生无法抢占锁的时候,拒绝被操作系统调度,用死循环占用核资源。下面是一把非常简单粗暴的自旋锁:
1 | atomic<bool> isLock = false; |
这种设计存在着一些问题,比如自旋时浪费资源过多等等,但是这些先不重要。重要的是可以先探究一下它作为一把自旋锁,能保证安全的合理性在哪里。
atomic凭什么保证原子性?
上面的自旋锁的粗暴实现,有一个很基础的前提,就是 isLock.compare_exchange_weak (expect,true) 这个操作对于多线程的并发操作来说是原子的,是多线程中最小的且不可并行化的操作。C++ 11宣称atomic类型的变量保证了该对象的原子性,那么具体在操作系统层面的实现基础是什么?
事实上,操作系统对原子性的操作保障无能为力,原子性的保障是来自于硬件层的支持。
在传统的CPU中,执行一条普通的指令是需要取指、译码、执行、写回结果等许多步骤的,这些指令是可以打断,可以相互穿插的,为了多线程的编程,CPU不得不专门提供一条Test and Exchange指令,把“检测内容,等于xx则修改其值”这样必须两三条指令才能完成的操作整合进一条指令来保障这个 isLock = xx 这个操作不被打断或者穿插。
如果多核条件下原子性还存在吗?
但是现代化的CPU都不能单核那么简单的,基本上都是多CPU在并发处理指令,并发处理指令则必定会遇到缓存数据与内存数据之间可能存在不一致的情况:如果线程a和b位于两个不同的CPU核上,那么确定保障了对同一个变量写的原子性吗?
单核心CPU的写策略
先简单回顾一下单核心CPU的两种写策略:
- 写直达:CPU每次访问修改数据时,无论数据在不在缓存中,都将修改后的数据同步到内存中,缓存数据与内存数据保持强一致性,这种做法影响写操作的性能。
- 写回:为了避免每次写操作都要进行数据同步带来的性能损失,写回策略里发生读写操作时:
- 如果缓存行中命中了数据,写操作对缓存行中数据进行更新,并标记该缓存行为已修改。
- 如果缓存中未命中数据,且数据所对应的缓存行中存放了其他数据:
- 若该缓存行被标记为已修改,读写操作都会将缓存行中现存的数据写回内存中,再将当前要获取的数据从内存读到缓存行,写操作对数据进行更新后标记该缓存行为已修改;
- 若该缓存行未被标记为已修改,读写操作都直接将当前要获取的数据从内存读到缓存行。写操作对数据进行更新后标记该缓存行为已修改。
多核心CPU的写策略
早年的多核CPU是通过锁总线来保障缓存的一致性的,这显然是不太合理的,其他CPU都只能进行等待,过于宽泛的颗粒度导致这个锁效率低下。之后逐渐进化成了写传播模式。
- 写传播:CPU进行缓存数据更新时需要告知其他CPU
如果出现了多个CPU对同一个数据操作的告知,则要求CPU对同一数据的修改应当保证事务串行化,否则会出现问题。
举个例子:CPU1、CPU2同时修改了数据A,CPU1把修改数据广播给CPU2、CPU3、CPU4,CPU2将修改数据广播给了CPU1、CPU3、CPU4,如果CPU3先接收到了CPU1的修改后接收到了CPU2的修改,而CPU4的接收顺序与3相反,此时3、4中A数据的值就可能不一致了,CPU1、CPU2互相接收对方的修改数据也会导致数据不一致的情况。
CPU的写传播是通过总线进行传播的,单纯的总线传播是无法保障事务的串行化的,需要依赖于缓存一致性协议(MESI)。
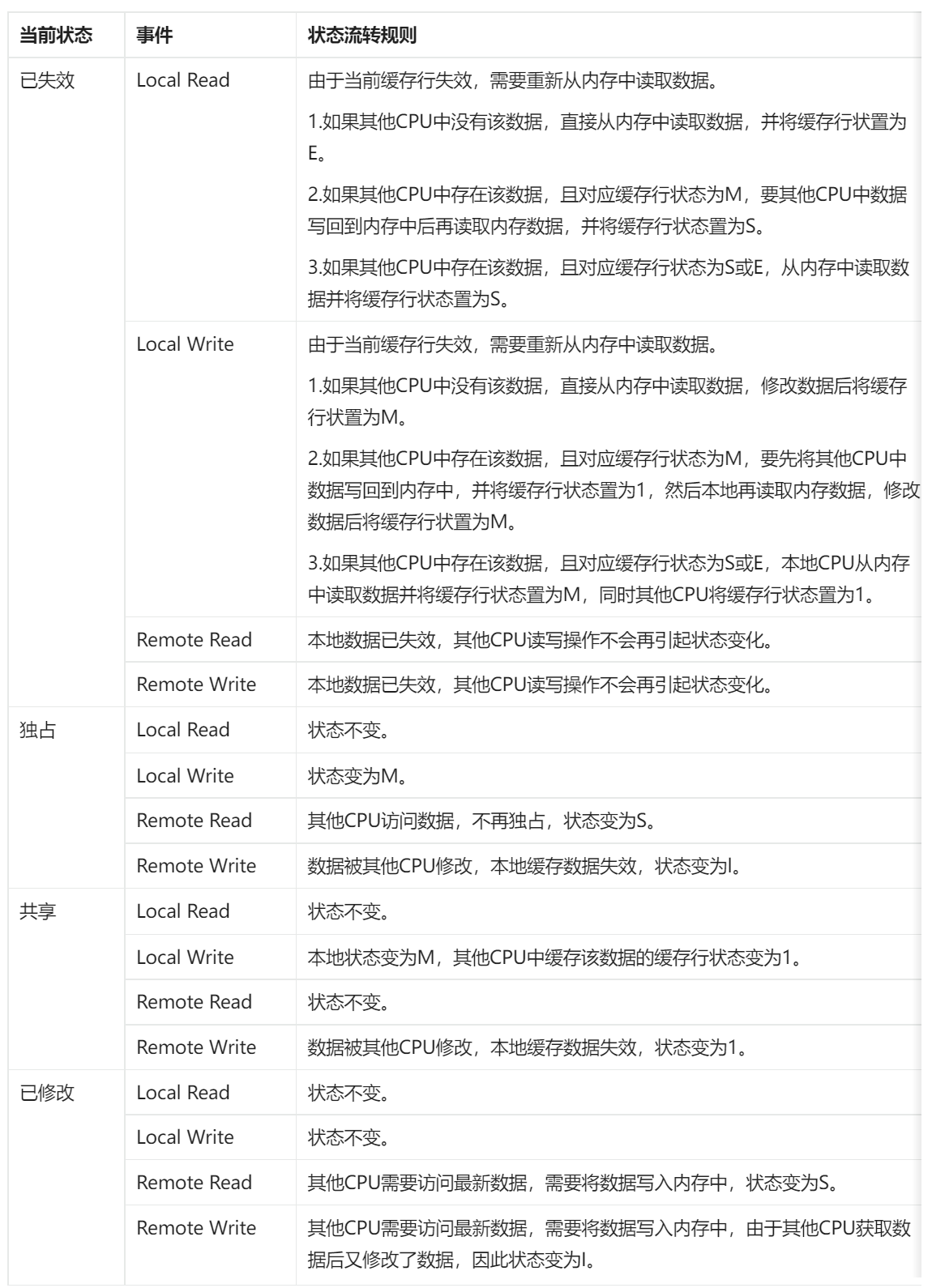
MESI首先规定了缓存的四种状态:
- _Modified_,已修改
- _Exclusive_,独占
- _Shared_,共享
- _Invalidated_,已失效
一些其他的引申
缓存一致性协议确实可以保障多核CPU缓存一致性,但是由于需要广播所以过于低效,所以实际CPU并不会遵守这个协议,为了提高性能CPU实际上存在着 Store Buffer和Invalidate Queue这两个机制,暂时只对这边做一个简单介绍,留待之后进行详细展开。
Store Buffer
CPU进行写传播的时候,为了实现异步性而引入的一个写缓冲区。
Invalidate Queue
对于Store Buffer中异步发送的指令,Invalidate Queue用队列的结构对指令得到的响应进行接收,并且根据先入先出的顺序进行消费。
是否可能存在指令乱序的问题?
跨线程的无依赖指令可能存在乱序
到目前为止,我们已经从捋清楚了在多核CPU的情况下,对某个atomic变量进行修改操作是原子性的这一事件的声明。接下来我们需要面对另外一个问题:指令乱序。
1 | //共享变量 |
由于指令重排的存在可能导致1、3、4、5、2的执行顺序的出现。这将超出我们对共享资源上访问顺序的控制。
指令重排的本质原因
指令重排的有两个层次的原因,一个是编译器对无依赖性的语句进行优化,一个是CPU的指令执行时候在流水线上的并发结构。
通过内存屏障解决指令乱序问题
内存屏障概念
内存屏障就是将内存/缓存的读写操作过程进行分隔。
缓存和内存之间的操作分为 Store 和 Load 两种。
- Store:将处理器缓存的数据刷新到内存中。
- Load:将内存存储的数据拷贝到处理器的缓存中。
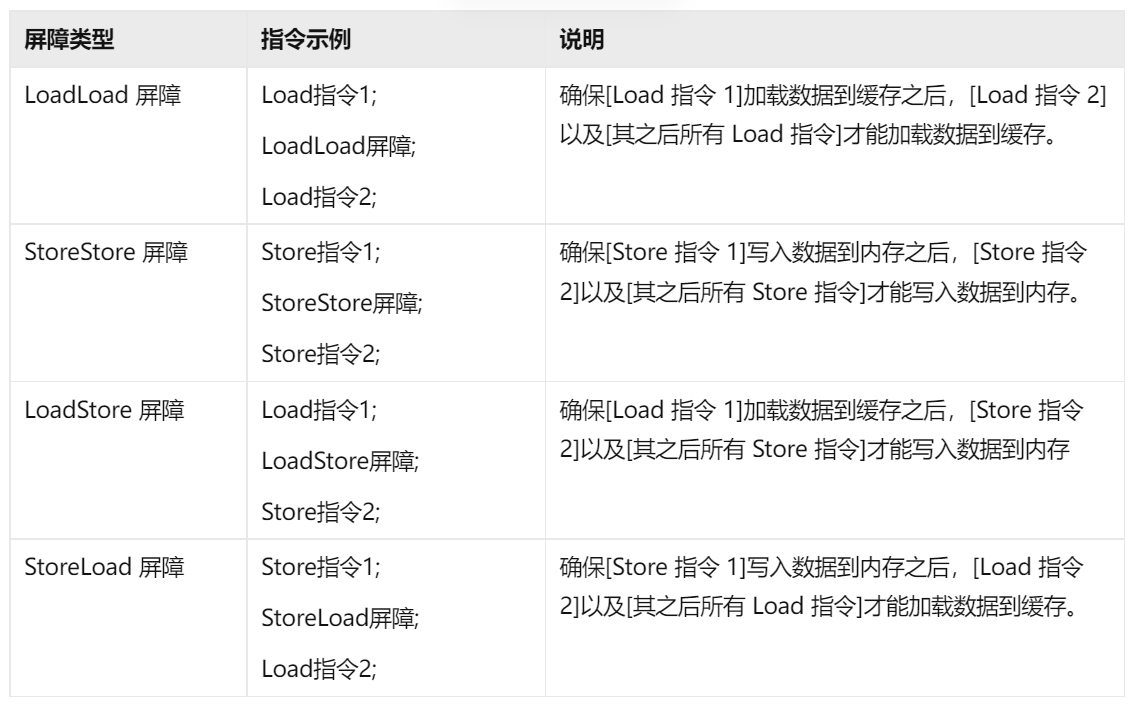
从上表中可以看出来,内存屏障的主要作用就是通过强制读写内存来间接避免指令重排。
在本质上是说是强制消费完了__tore Buffer和Invalidate Queue中的内容。
所以,在之前那个程序中进行如下更改就可以避免指令重排,强制保障执行顺序为12345:
1 | //共享变量 |
C++对内存屏障提供的接口
假设在编程过程中存在大量原子读写操作,如果全部操作都不允许指令重排,也就是严格保证顺序一致性,虽然运行结果很容易符合开发者编程预期,降低了开发难度,但是这样会很大程度影响 CPU 执行性能。
因此C++ 通过引入内存序接口,提供了控制 CPU 缓存同步的能力给开发者,让内存读写的顺序更加灵活可控。C++ 的内存序允许按照批次保证内存读写顺序,而不必对每一个读写操作保证,也就是说批次和批次之间保持顺序一致性,批次内部保持松散顺序就行。
C++提供了六种严格度不同的内存序:
1 | typedef enum memory_order |
memory_order_relaxed是最松散的内存序,使用这种内存序的多个内存操作之间同一个线程里还是按照happens-before(happens-before 指的是内存模型中两项操作的顺序关系。例如说操作 A 先于操作 B,也就是说操作 A 发生在操作 B 之前,操作 A 产生的影响能够被操作 B 观察到。这里的「影响」包括:内存中共享变量的值、发送了消息、调用了方法等)的关系执行,但是不同线程之间的执行关系是任意的。
在以下代码的示例中,使用了memory_order_relaxed内存序,执行顺序有可能是0或者42
1 | atomic<int> guard(0); |
memory_order_seq_cst在底层同时使用了 StoreStore 屏障和 LoadLoad 屏障来实现,因此保证了内存读写顺序和指令顺序一是致的。这种内存序要严格控制每一次内存读写的顺序,所以执行效率是所有内程序里最低的。顺序一致性序列是完全保证内存读写顺序和指令顺序一致的,所以最终的 p 值为 42。
1 | atomic<int> guard(0); |
memory_order_release 和 memory_order_acquire是释放和获取序列。
release 底层使用了 StoreStore 屏障,保证在此内存操作之前的所有 Store 操作都不可能重排到此操作之后;也可以理解为这个操作使 CPU 将所有缓存写入了内存,使其他缓存可见。
acquire 底层使用了 LoadLoad 屏障,保存在此内存操作之后的所有 Load 操作都不可能重排到此操作之前;也可以理解为这个操作使 CPU 将所有抛弃了所有缓存,重新从内存读取数据。
使用这种内存序,保证了 std::memory_order_release 之前的 Store 操作按一个批次同步到其他缓存,同时 std::memory_order_acquire 之后的 Load 操作按一个批次从内存加载数据到缓存,保证了局部的一致性。
这种内存序因为是按批次来同步缓存的,所以性能优于顺序一致性序列,但是又没有松散序列高效。
在下面代码中,就是保证写线程写完之后,读线程才开始读的局部一致性,所以最终的 p 值为 42。
1 | atomic<int> guard(0); |
memory_order_release 和 **memory_order_consume **是数据依赖序列。
memory_order_consume 的底层实现并不使用内存屏障,而是分析数据依赖来保证数据依赖链上的指令的顺序一致性。
在从内存加载数据到缓存的时候,根据数据依赖链的顺序去加载。写入内存还是使用 memory_order_release 的策略不变。这种内存序在多平台方面,支持不是很好,有一些硬件设备并不支持这种内存序列,因此它会被退化成获取-释放序列。
其他想说的事情
因为这个是我整合了几篇杂乱随记出来的内容,虽然经过我对主线的梳理,但还是感觉内容的破碎感很强,我写到六种内存序后戛然而止,颇有种意犹未尽之感。
我感觉还有很多东西可以补充在这篇博客上面,包括CPU的流水线结构,Store Buffer和Invalidate Queue机制,CPU多核心进行同步的细节等,这些我自觉是与无锁编程相关的内容之后都会逐步在这篇的基础上继续补充,希望它越来越完善。