
这一篇主要介绍了缓存友好编程的一些基本原则和使用中需要注意的点。
局部性原理
在编程过程中,局部性原理的存在是缓存友好编程这一概念存在的基础。局部性原理一般可分为时间局部性和空间局部性。
时间局部性指的是被引用过一次的内存位置很可能在不远的将来再被多次引用。空间局部性指的是如果一个内存位置被引用了一次,那么程序很可能在不远的将来引用附近的一个内存位置。
在我们编程中,大量的数据结构存在顺序引用模式,如数组,列表等,这些顺序的数据结构就是空间局部性的主要来源。如果存在循环语句的话,就会对同一指令进行多次执行,这是时间局部性的主要来源。
缓存行结构
继续说空间局部性,为什么会出现空间局部性,是因为处理器存在缓存行的概念。
缓存行是处理器一次缓存读写操作的最小长度单位。当我们的CPU试图访问一个int类型(4字节)的内存地址时,包含该地址的整个缓存行(32字节)将被加载进我们的Cache。也就是说,一次缓存行的读取相对于我们一个变量的读取,完全是有空间冗余的操作。如果我们在接下来试图访问连续的下一个int值时,可以跳过将缓存行从内存中加载到缓存中中的这个步骤,直接命中缓存。
这一部分的开销的节省是否有必要,可以从下表发现,从寄存器到主存的逐级cache,访问速度是指数级变化的,极端情况下直接在L1命中缓存和到内存中寻址,相差100倍的时钟周期。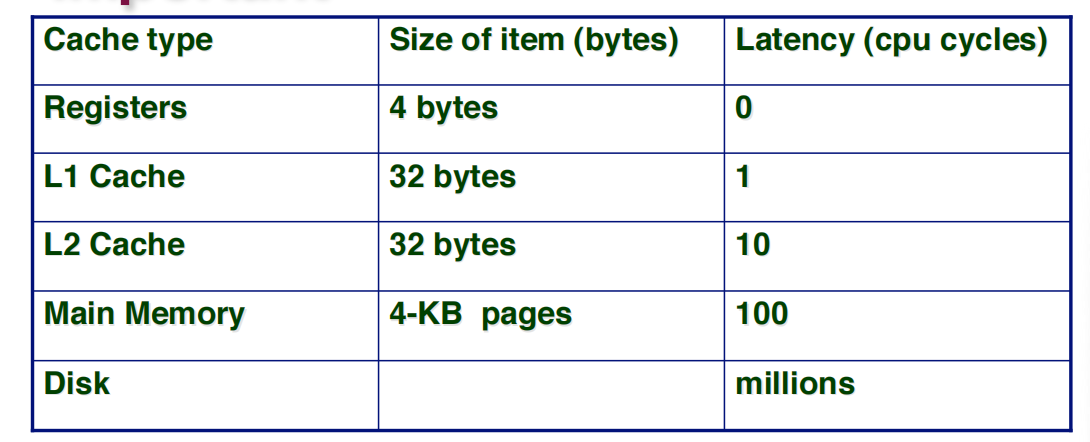
缓存命中的问题
代码示例
在冷缓存,32位机器,32字节缓存行大小的机器下,如下两种代码的便利方式有着大相径庭的缓存命中率。
1 | //缓存命中率7/8 |
编程原则
- 保持尽可能小的工作集(时间局部性)
- 使用小步幅连续寻址(空间局部性)
缓存优化技巧
- 当获取线性数据时,尽量使用vector和array
- 经常访问的数据,在内存中应当是相邻的
- 使用数据数组替换指针数组
- 类的大小需要是cache line大小的倍数:手动的填充使其满足cache line 或者告诉编译器自动帮我们填充
- 有效地访问你的矩阵中的数据
反直觉的False Sharing
在之前提到的内容中,把数据尽可能地连续放入缓存行,似乎是一种非常高效的便于访问的方法。
但是事实上,如果不合理地使用缓存,将会出现反直觉地false sharing的问题。
false sharing的成因
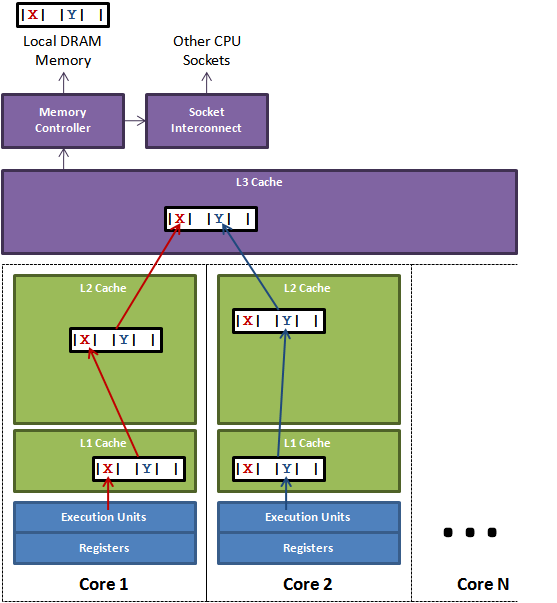
如图所示,一个运行在处理器 core1上的线程想要更新变量 X 的值,同时另外一个运行在处理器 core2 上的线程想要更新变量 Y 的值。但是,这两个频繁改动的变量都处于同一条缓存行。两个线程就会轮番发送Request For Owner消息(写请求之前的独占声明),占得此缓存行的拥有权。当 core1 取得了拥有权开始更新 X,则 core2 对应的缓存行需要设为 I 状态。当 core2 取得了拥有权开始更新 Y,则 core1 对应的缓存行需要设为 I 状态(失效态)。轮番夺取拥有权不但带来大量的 RFO 消息,而且如果某个线程需要读此行数据时,L1 和 L2 缓存上都是失效数据,只有 L3 缓存上是同步好的数据。从前一篇我们知道,读 L3 的数据非常影响性能。更坏的情况是跨槽读取,L3 都要 miss,只能从内存上加载。
表面上 X 和 Y 都是被独立线程操作的,而且两操作之间也没有任何关系。只不过它们共享了一个缓存行,但所有竞争冲突都是来源于共享。
false sharing的解法
一个解决思路,就是让不同线程操作的对象处于不同的缓存行即可。
具体方法就是缓存行填充(Padding) 。我们使得可能产生写冲突的对象处于不同的缓存行,就避免了伪共享( 64 位系统超过缓存行的 64 字节也无所谓,只要保证不同线程不操作同一缓存行就可以)。